Creating a Custom Time-Series Cross-Validator in PySpark
02 July 2024I often build robust machine learning pipelines in PySpark qua my job, and while the built-in machine learning library is very powerful, sometimes I find it lacking. Fortunately, we can extend it ourselves to suit our needs. Here, I show you how I built a custom time-series cross-validator in PySpark.
Understanding Time-Series Cross-Validation
Unlike traditional k-fold cross-validation, which splits the data randomly into \(k\) folds, time-series cross-validation involves splitting the data into consecutive periods, such that the temporal order is respected. The training set of each fold consists of past data, while the validation set consists of more recent data. This approach mimics how the model would be used in practice for forecasting.
There are different ways of creating these folds in time-series cross-validation. Two of the most common ways are rolling windows and expanding windows. In the rolling window setup, the training sets have the same size as we let the beginning of the training set roll forward. On the other hand, the expanding window setup enables the training to expand as the start of the training set is kept constant.
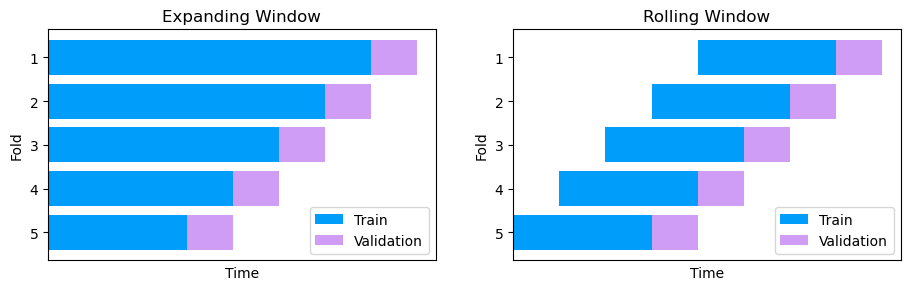
Implementing Time-Series Cross-Validation in PySpark
To implement time-series cross-validation in PySpark, we can extend the functionality of the CrossValidator class from pyspark.ml.tuning. By inspecting the PySpark source code, we see that the _fit method first creates the folds by calling the _kFold method. In particular, this is the code that creates the folds:
# PySpark version: 3.5.0
def _kFold(self, dataset: DataFrame) -> List[Tuple[DataFrame, DataFrame]]:
nFolds = self.getOrDefault(self.numFolds)
foldCol = self.getOrDefault(self.foldCol)
datasets = []
if not foldCol:
# Do random k-fold split.
seed = self.getOrDefault(self.seed)
h = 1.0 / nFolds
randCol = self.uid + "_rand"
df = dataset.select("*", rand(seed).alias(randCol))
for i in range(nFolds):
validateLB = i * h
validateUB = (i + 1) * h
condition = (df[randCol] >= validateLB) & (df[randCol] < validateUB)
validation = df.filter(condition)
train = df.filter(~condition)
datasets.append((train, validation))
else:
[...]
return datasets
The method creates a new column with random numbers and uses it to create train-validation pairs by filtering on it. We can implement our custom time-series cross-validator by overriding this method.
Solution
from multiprocessing.pool import ThreadPool
from pyspark import keyword_only
from pyspark.ml.param import Params, Param, TypeConverters
from pyspark.ml.tuning import CrossValidator
class tsCrossValidator(CrossValidator):
"""
Custom validator for time-series cross-validation.
This class extends the functionality of PySpark's CrossValidator to support
walk-forward time-series cross-validation. It splits the dataset into
consecutive periods with each fold using data from the past as training
and the most recent period as validation.
In particular, it overrides the _kFold method (which is used in the fit method)
"""
datetimeCol = Param(
Params._dummy(),
"datetimeCol",
"Column name for splitting the data",
typeConverter=TypeConverters.toString)
timeSplit = Param(
Params._dummy(),
"timeSplit",
"Length of time to leave in validation set. Should be some sort of timedelta or relativedelta")
gap = Param(
Params._dummy(),
"gap",
"Length of time to leave bas gap between train and validation")
disableExpandingWindow = Param(
Params._dummy(),
"disableExpandingWindow",
"Boolean for disabling expanding window folds and taking rolling windows instead.",
typeConverter=TypeConverters.toBoolean)
@keyword_only
def __init__(self, estimator=None, estimatorParamMaps=None, evaluator=None,
numFolds=3, datetimeCol = 'date', timeSplit=None,
gap=None, disableExpandingWindow=False, parallelism=1, collectSubModels=False):
super(tsCrossValidator, self).__init__(
estimator=estimator,
estimatorParamMaps=estimatorParamMaps,
evaluator=evaluator,
numFolds=numFolds,
parallelism=parallelism,
collectSubModels=collectSubModels
)
self._setDefault(gap=None, datetimeCol='date', timeSplit=None, disableExpandingWindow=False)
# Explicitly set the provided values
self._set(gap=gap, datetimeCol=datetimeCol, timeSplit=timeSplit, disableExpandingWindow=disableExpandingWindow)
kwargs = self._input_kwargs
self._set(**kwargs)
def getDatetimeCol(self):
return self.getOrDefault(self.datetimeCol)
def setDatetimeCol(self, datetimeCol):
return self._set(datetimeCol=datetimeCol)
def getTimeSplit(self):
return self.getOrDefault(self.timeSplit)
def setTimeSplit(self, timeSplit):
return self._set(timeSplit=timeSplit)
def getDisableExpandingWindow(self):
return self.getOrDefault(self.disableExpandingWindow)
def setDisableExpandingWindow(self, disableExpandingWindow):
return self._set(disableExpandingWindow=disableExpandingWindow)
def getGap(self):
return self.getOrDefault(self.gap)
def setGap(self, gap):
return self._set(gap=gap)
def _kFold(self, dataset):
nFolds = self.getOrDefault(self.numFolds)
datetimeCol = self.getOrDefault(self.datetimeCol)
timeSplit = self.getOrDefault(self.timeSplit)
gap = self.getOrDefault(self.gap)
disableExpandingWindow = self.getOrDefault(self.disableExpandingWindow)
datasets = []
endDate = dataset.agg({datetimeCol : 'max'}).collect()[0][0]
trainLB = dataset.agg({datetimeCol: 'min'}).collect()[0][0]
for i in reversed(range(nFolds)):
validateUB = endDate - i * timeSplit
validateLB = endDate - (i + 1) * timeSplit
trainUB = validateLB - gap if gap is not None else validateLB
val_condition = (dataset[datetimeCol] > validateLB) & (dataset[datetimeCol] <= validateUB)
train_condition = (dataset[datetimeCol] <= trainUB) & (dataset[datetimeCol] >= trainLB)
validation = dataset.filter(val_condition)
train = dataset.filter(train_condition)
datasets.append((train, validation))
if disableExpandingWindow:
trainLB += timeSplit
return datasets
Conclusion
That’s it! You can replace your CrossValidator with the tsCrossValidator instead and fit your pipelines and tune your hyperparameters like you usually would.
Further reading
I found the following particularly helpful:
- How to Backtest Machine Learning Models for Time Series Forecasting (last visited 2024-01-14)